Learning to Estimate Hidden Motions with Global Motion Aggregation
IEEE International Conference on Computer Vision (ICCV), 2021.
We obtained the state-of-art results by integrating global motion features.
[paper]
Learning Optical Flow from a Few Matches
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
We show that high performance optical flow estimation can be achieved without using dense cost volumes.
[paper]
Bidirectionally Self-Normalizing Neural Networks
arXiv, 2020.
We theoretically solve the vanishing/exploding gradients problem in neural networks. Key idea: constrain signal norm in both directions via a new class of activation functions and orthogonal weight matrices.
[paper]
Devon: Deformable Volume Network for Learning Optical Flow
IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
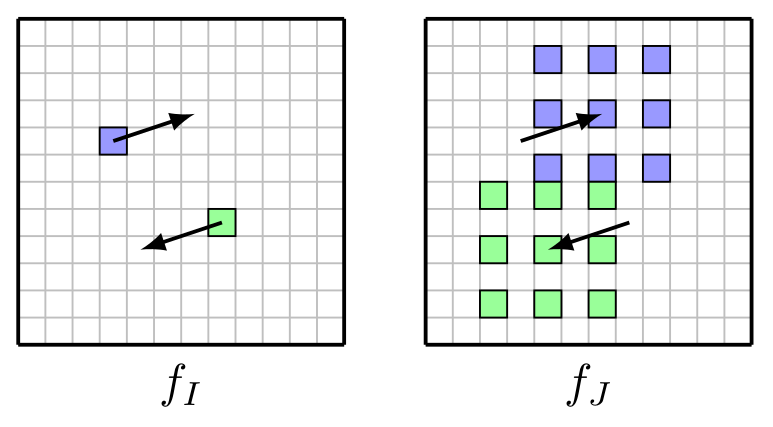 We pointed out the problem of image warping in estimating optical flow and proposed the deformable cost volume to solve the problem.
We pointed out the problem of image warping in estimating optical flow and proposed the deformable cost volume to solve the problem.
[paper]
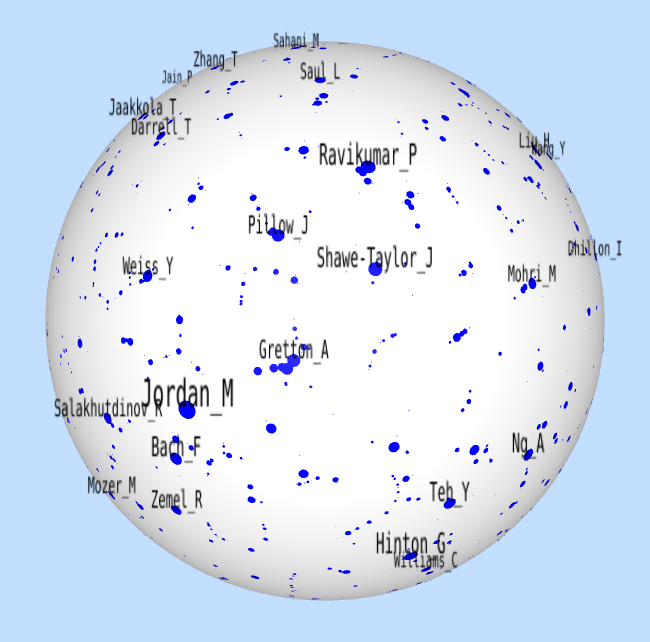
Doubly Stochastic Neighbor Embedding on Spheres
Pattern Recognition Letters, 2019.
Learning Image Relations with Contrast Association Networks
International Joint Conference on Neural Networks (IJCNN), 2019.
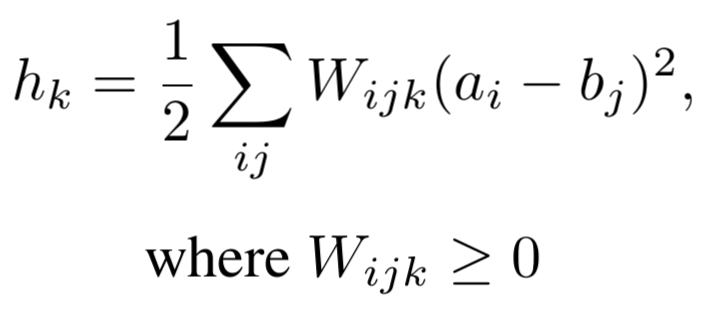
We proposed a new neural network module, Contrast Association Units, to model the relations between two sets of input variables.
[paper]
Block Mean Approximation for Efficient Second Order Optimization
ICML workshop on Modern Trends in Nonconvex Optimization for Machine Learning, 2018.
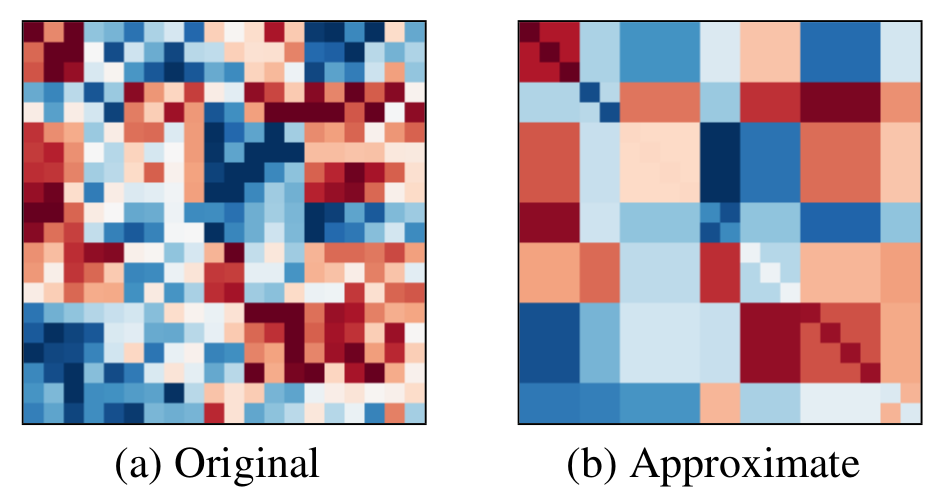 We proposed a new matrix approximation method which allows efficient matrix inversion. We then applied the method to second order optimization algorithms for training neural networks.
We proposed a new matrix approximation method which allows efficient matrix inversion. We then applied the method to second order optimization algorithms for training neural networks.
[paper]
Oblivious Neural Network Predictions via MiniONN Transformations
ACM Conference on Computer and Communications Security (CCS), 2017.
We proposed a new method for privacy-preserving predictions with trained
neural networks.
[paper]
A Fast Projected Fixed-Point Algorithm for Large Graph Matching
Pattern Recognition, 2016.
 We designed a fast graph matching algorithm with time complexity
O(n^3) per iteration, where n is the size of a graph. We
proved its convergence rate. It takes within 10 seconds to match two graphs of
1000 nodes on a PC.
We designed a fast graph matching algorithm with time complexity
O(n^3) per iteration, where n is the size of a graph. We
proved its convergence rate. It takes within 10 seconds to match two graphs of
1000 nodes on a PC.
[paper]
Unsupervised Learning on Neural Network Outputs
International Joint Conference on Artificial Intelligence (IJCAI), 2016.
 We found visual attributes of object classes can be unsuperisedly learned by applying Independent Component Analysis on the softmax outputs of a trained ConvNet. We showed such attributes can be useful for object recognition by performing zero-shot learning experiments on the ImageNet dataset of over 20,000 object classes.
We found visual attributes of object classes can be unsuperisedly learned by applying Independent Component Analysis on the softmax outputs of a trained ConvNet. We showed such attributes can be useful for object recognition by performing zero-shot learning experiments on the ImageNet dataset of over 20,000 object classes.
[paper]
An Algorithm for Maximum Common Subgraph of Planar Triangulation Graphs
Graph-Based Representations in Pattern Recognition (GbR), 2013.
 We designed a fast Maximum Common Subgraph (MCS) algorithm for Planar Triangulation Graphs. Its time complexity is O(mnk), where n is the size of one graph, m is the size of the other graph and k is the size of their MCS.
We designed a fast Maximum Common Subgraph (MCS) algorithm for Planar Triangulation Graphs. Its time complexity is O(mnk), where n is the size of one graph, m is the size of the other graph and k is the size of their MCS.
[paper]
Traveling Bumps and Their Collisions in a Two-Dimensional Neural Field
Neural Computation, 2011.
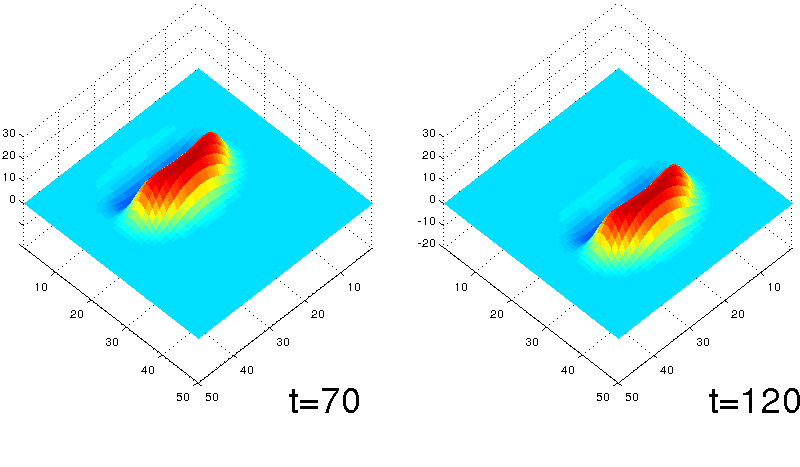 We found a unique traveling bump solution, which was unknown to exist before, in a set of two-dimensional neural network equations.
We found a unique traveling bump solution, which was unknown to exist before, in a set of two-dimensional neural network equations.
[paper]